Ordinal Regression as a Model for Signal Detection
R
statistics
code
ordinal regression
signal detection theory
Author
Mattan S. Ben-Shachar
Published
October 6, 2022
Preface
I was basically done with this blog post when I came across Matti Vuorre’s post on the same exact topic. Matti goes into all the details, and really the present post can be seen as a brief account of all the cool things the probit-approach-to-SDT can do. I’m only posting this here because I really like my plots 🤷
Previously, we’ve seen that for data from a binary decision signal detection task, we can use a probit binomial regression model (like a logistic regression, but with a probit link function) to estimate the two main parameters of signal detection theory (SDT): the sensitivity and the bias.
In this post I would like to show how this idea can be extended to multiple response SDT tasks by using an ordinal probit regression model.
The Data
Imagine the following task: after being presented with 20 images of dogs, you are presented with 300 new images of dogs, and you have to decide for each dog if it appeared in the training set (“Old”) or not (“New”).
In a binary decision task, you would simply indicate “New” or “Old”, but in this task you have multiple response options - from 1 to 6, with 1 = “Feels New” and 6 = “Feels Old”. We can call this scale a “feelings numbers” scale.
After going over all 30 photos, you have
STD_data
# A tibble: 12 × 3
Truth Response N
<fct> <ord> <dbl>
1 New Confidence1 35
2 New Confidence2 31
3 New Confidence3 26
4 New Confidence4 22
5 New Confidence5 19
6 New Confidence6 17
7 Old Confidence1 14
8 Old Confidence2 20
9 Old Confidence3 22
10 Old Confidence4 27
11 Old Confidence5 32
12 Old Confidence6 35
Where N is the number of responses in each condition and response level.
Modeling with Classic SDT
We can use Siegfried Macho’s R code to extract the SDT parameters. In this case, they are:
Sensitivity - The distance between the two (latent) normal distributions. The further they are, the more “distinguishable” the Old and New images are from each other.
5 Threshold - One between each pair of consecutive possible responses. Perceived “stimulation” above each threshold leads to a decision in that category.
(These will probably make sense when we present them visually below.)
First, we’ll model this with classical SDT:
SDT_equal <-SDT.Estimate(data = STD_data[["N"]],test =TRUE,# We have 2 option: Old / New; We'll assume equal variancen =list(n.sdt =2, restriction ="equalvar")) SDT.Statistics(SDT_equal)[["Free.parameters"]]
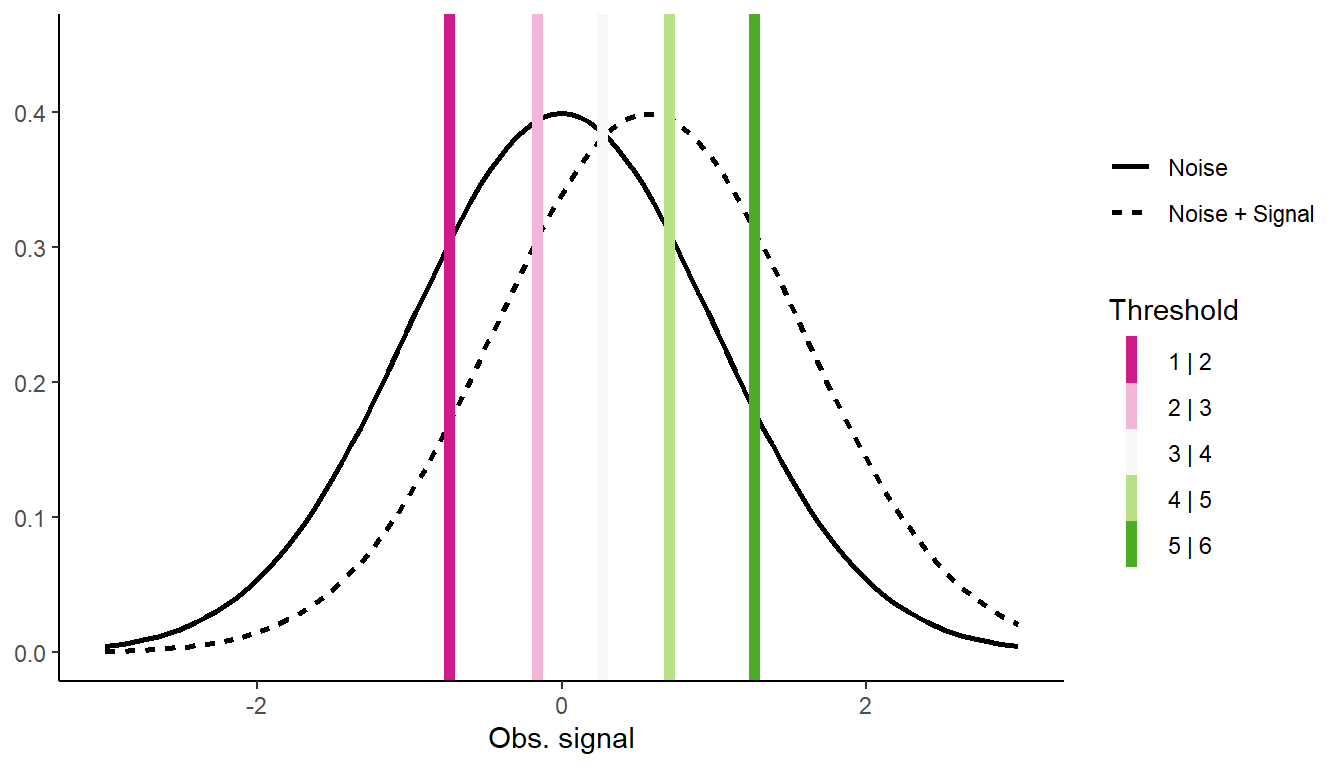
We can also model this data with a Probit Cumulative Ordinal model, predicting the Response from the Truth: - The slope of Truth indicates the effect of the true image identity had on the response pattern - this is sensitivity.
- In an ordinal model, we get k-1 “intercepts” (k being the number of unique responses). Each intercept represents the value above which a predicted value will be binned into the next class. There represent our shreshold.
mean2 <-coef(m_equal)[6]Thresholds <-coef(m_equal)[1:5]ggplot() +# Noisestat_function(aes(linetype ="Noise"), fun = dnorm,linewidth =1) +# Noise + Signalstat_function(aes(linetype ="Noise + Signal"), fun = dnorm, args =list(mean = mean2),linewidth =1) +# Thresholdsgeom_vline(aes(xintercept = Thresholds, color =names(Thresholds)),linewidth =2) +scale_color_brewer("Threshold", type ="div", palette =2,labels =paste0(1:5, " | ", 2:6)) +labs(y =NULL, linetype =NULL, x ="Obs. signal") +expand_limits(x =c(-3, 3), y =0.45) +theme_classic()
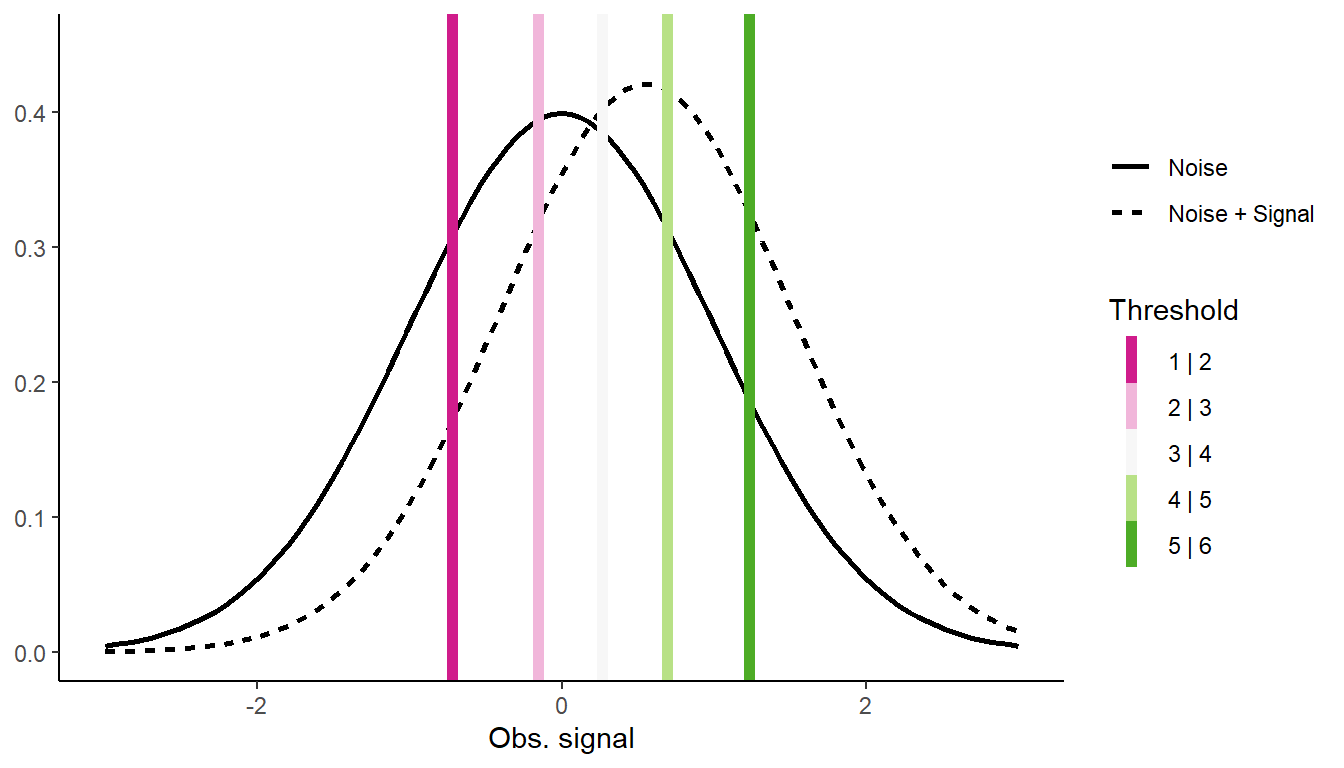
Unequal Variance
The standard model of SDT assumes that the Noise and the Noise + Signal distribution differ only in their mean; that is, N+S is a shifted N distribution. This is almost always not true, with \(\sigma_{\text{N+S}}>\sigma_{\text{N}}\).
To deal with this, we can also estimate the variance of the N+S distribution.
First, with the classic SDT model:
SDT_unequal <-SDT.Estimate(data = STD_data[["N"]],test =TRUE,# We have 2 option: Old / New; Not assuming equal variancen =list(n.sdt =2, restriction ="no")) SDT.Statistics(SDT_unequal)[["Free.parameters"]]
And with a probit ordinal regression, but allow the latent scale to vary:
m_unequal <-clm(Response ~ Truth, scale =~ Truth, # We indicate that the scale is a function of the underlying distdata = STD_data, weights = N,link ="probit")parameters::model_parameters(m_unequal) |> insight::print_html()
Model Summary
Parameter
Coefficient
SE
95% CI
z
p
Intercept
Confidence1|Confidence2
-0.72
0.11
(-0.93, -0.50)
-6.51
< .001
Confidence2|Confidence3
-0.16
0.10
(-0.34, 0.03)
-1.61
0.107
Confidence3|Confidence4
0.27
0.10
(0.08, 0.45)
2.80
0.005
Confidence4|Confidence5
0.69
0.10
(0.49, 0.90)
6.66
< .001
Confidence5|Confidence6
1.23
0.13
(0.98, 1.49)
9.50
< .001
Location Parameters
Truth (Old)
0.55
0.12
(0.31, 0.80)
4.49
< .001
Scale Parameters
Truth (Old)
-0.05
0.12
(0.31, 0.80)
4.49
< .001
The scale parameter needs to be back transformed to get the sd of the N+S distribution: \(e^{-0.05}=0.95\), and so one again the estimated values are identical!
mean2 <-coef(m_unequal)[6]sd2 <-exp(coef(m_unequal)[7])Thresholds <-coef(m_unequal)[1:5]ggplot() +# Noisestat_function(aes(linetype ="Noise"), fun = dnorm,linewidth =1) +# Noise + Signalstat_function(aes(linetype ="Noise + Signal"), fun = dnorm, args =list(mean = mean2, sd = sd2),linewidth =1) +# Thresholdsgeom_vline(aes(xintercept = Thresholds, color =names(Thresholds)),linewidth =2) +scale_color_brewer("Threshold", type ="div", palette =2,labels =paste0(1:5, " | ", 2:6)) +labs(y =NULL, linetype =NULL, x ="Obs. signal") +expand_limits(x =c(-3, 3), y =0.45) +theme_classic()
SDT with N and N+S distributions, and the 5 thresholds.
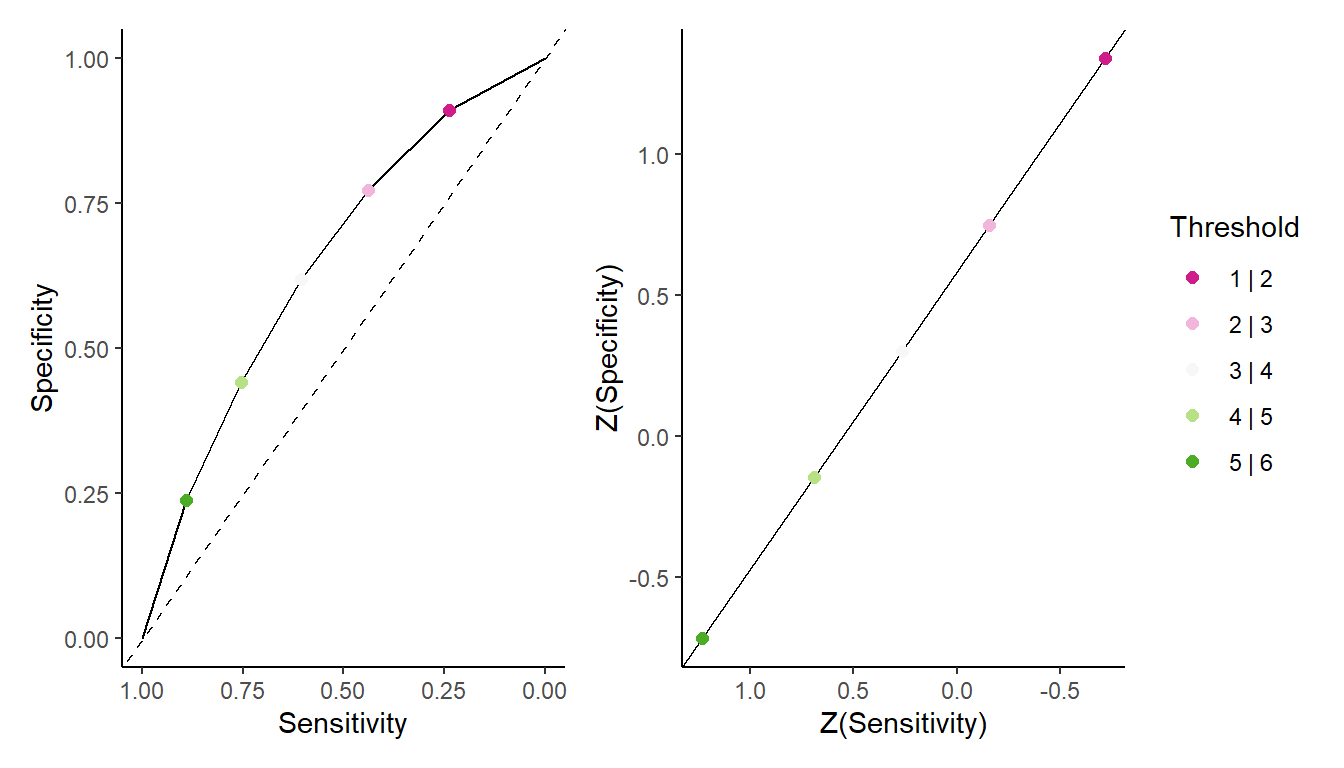
ROC Curve or ROC Curves?
An additional check we can preform is whether the various responses are indeed the product of single ROC curve. We do this by plotting the ROC curve on a inv-normal transformation (that is, converting probabilities into normal quantiles). Quantiles that fall on a straight line indicate they are part of the same curve.
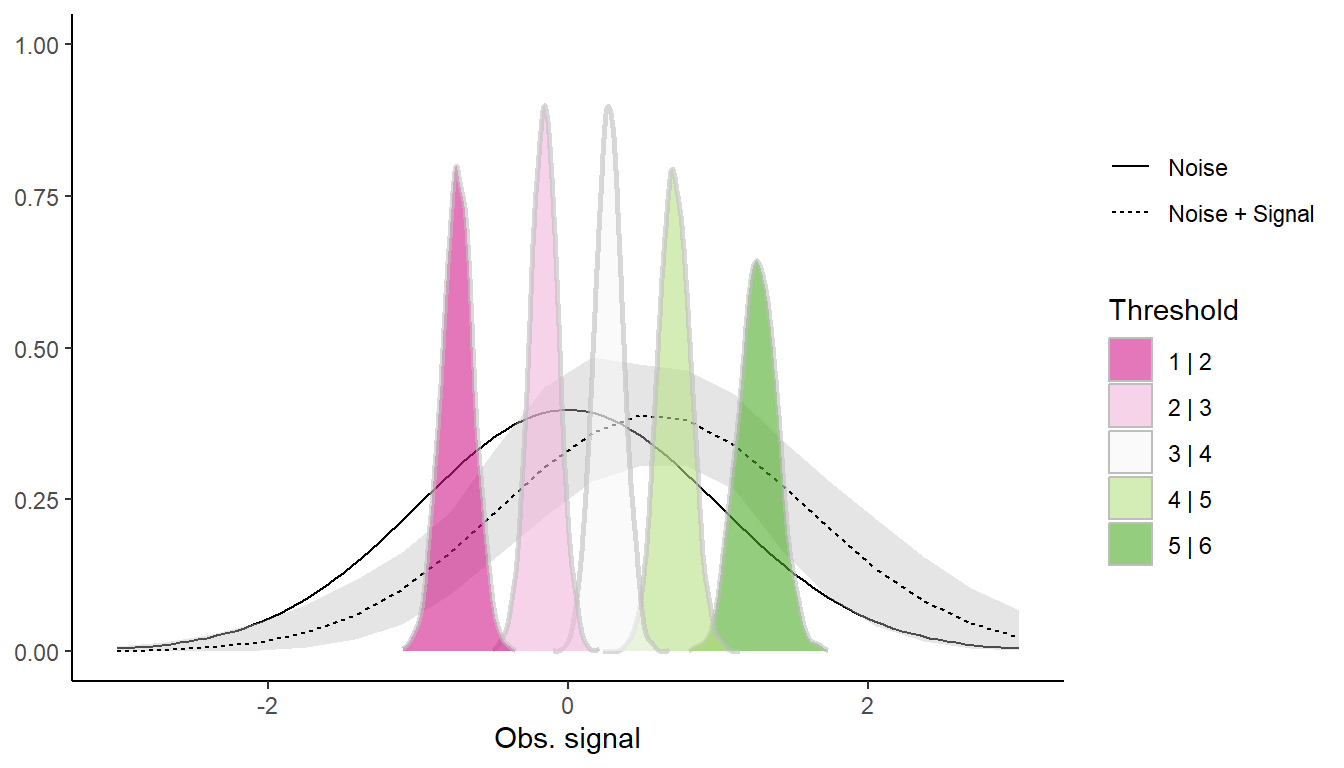
In brms we will use the cumulative() family, which has a family-parameter called disc which gives the standard deviation of the latent distributions. I will set some weak priors on the mean and standard deviation of the N+S distribution, and I will also set the standard deviation of the N distribution to 1 (on a log scale, to 0) using the constant(0) prior.